Source
XML documents Mise à jour mai 2024
Fil des révisions
-
mai 2024
Ajout de la documentation des xdocs
-
mars 2022
Création de la page
-
mai 2024Ajout de la documentation des xdocs
-
mars 2022Création de la page
Cette page traite de la façon dont sont organisées les données publiées dans ce site qui peuvent être des images ou du texte.
Organisation des données
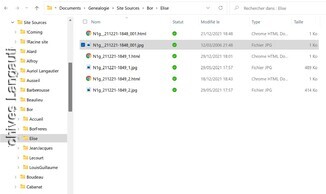
Destiné à présenter des documents, c'est autour des pages de document que les données ont été organisées. Pour chaque page, il est nécessaire de conserver une image et du texte associé.
Archives destinées à durer, chaque couple (image, données) est conservé dans deux fichiers de même nom distingués par leur extension (.jpg et .html) ce qui présente les avantages suivants :
Pas de logiciel type base de données pour le stockage à acquérir puis maintenir.
Eviter de créer un bloc de 30 Go de données à manipuler comme un tout avec 15 000 images et 15 000 objets XML stockés à l'intérieur.
Sauvegarde immédiate et réplication de chaque fichier sur un second PC assurée par OneDrive
Sauvegardes incrémentales rapides avec FreeFileSync sur un support amovible.
Historisation par fichier et dépannage simplifié avec One Drive.
Système de gestion de fichiers Windows très performant en lecture / écriture.
Bibliothèque XML : VBA Msxml2.DOMDocument qui assure
la conformité de la syntaxe XML ce qui assure une bonne base de départ pour tous les traitements qui vont suivre et donc en sortie pour la conformité du code HTML généré ;
le moteur de recherche XPath pour aller chercher ensuite des tags ou des attributs ;
des fonctions pour modifier le XML de façon pratique et sure ;
l’interface XSLT qui est aussi très pratique pour générer du HTML à partir de l’XML.
Les fichiers (.jgp-.html ) de chaque page sont conservées dans un répertoire.
Extension des fichiers
En toute rigueur, c'est une extension .xml qui aurait dû être utilisée.
Les répertoires de chaque famille sont conservés dans un répertoire.
Cet ensemble est totalement indépendant de la navigation du site.
Fichiers xdoc, texte associé à un document
La structure XML comporte trois zones distinctes :
<xdoc file="Sommaire\XMLdocuments\Y0h_220306-1353_2" img="src:1622x973; FileSize:153 Kb 153336; web:1280x768; th:682x389" key="row-class:blog; col-md:6; fit:6 1622/973; aspect-ratio:7/4-1,753; th:682x389; crop:+0+0%[3;">
<!-- Tag xdoc avec les informations techniques associées au document -->
<fixed>
<!-- Code XML du texte à afficher avant l’image -->
<!-- Il peut contenir soit des balises XML à traiter à la construction de la page -->
<!-- Soit du code HTML à afficher -->
</fixed>
<float>
<!-- Code XML du texte à afficher à gauche de l’image -->
</float>
</xdoc>
Les attributs du tag xdoc sont les suivants :
| file | lecture seule |
|---|---|
| "Sommaire\XMLdocuments\Y0h_220306-1353_2" | nom du fichier, il n’est en principe avec le nom du fichier disponible dans le XML. Y0h est un préfixe spécifique à ce répertoire, le second élément une date et le troisième un numéro d’ordre |
img | Lecture seule |
| ImageSize:1887x942 | cache local du tag Exifde même nom |
| FileSize:497 ko | cache local pour afficher cette information dans le XML sans avoir à aller la chercher dans Windows. Un jour ou l’autre ce sera à utiliser pour réduire les images dont la taille est manifestement trop grande (au-delà de 10 MO pour certaines) |
| Orientation=Rotate 90 CW | cache local du tag Exif. Il est utilisé par ImageMagik pour faire les rotations qui conviennent. Si la valeur est "Horizontal (normal)", le tag n'est pas recopié dans le xdoc. |
| class="font-monospace">XResolution:120 in. | cache local du tag Exif pour la résolution de l'appareil de photo ou du scanner |
| Autres tags Exif | voir la page tag Exif |
| web:1280x768 | dimension en pixel de l’image pour le site, mise à jour par VBA du CMS word et utilisée pour convertir le .jpg original en une image plus petite pour le site avec le filigrane (conversion réalisée par VBA CMS en utilisant ImageMagik). C’est celle qui s’affiche lors du double-clic sur la vignette. |
| th:682x389 | Idem pour la vignette (thumb) sur le site, à noter, qu’il était prévu au départ de n’afficher que des vignettes et que par la suite, comment ci-dessus, la dite vignette peut être aussi grande qu’utile. | key | mise à jour par le code VBA du CMS Word |
| key="…" | paramètres pour traiter l’image, décrit par ailleurs |
Pour permettre malgré tout de créer des paragraphes dans la page sans image associée, il est possible de créer une image vide. Elle se repère aussi facilement dans le répertoire à sa taille de 1 ko ; dans le XML, elle apparait ainsi :
<xdoc file="Sommaire\XMLdocuments\Y0h_220306-1353_3" img="null;" key="row-class:blog;">
<fixed></fixed>
<float></float>
</xdoc>
Tags XML
En théorie, nos fichiers XML pourraient ne contenir que du code HTML à intégrer pour construire la page du site. Cependant, il est apparu que certains affichages nécessitaient soit des opérations annexes (comme les icones pour les cartes), soit du code HTML beaucoup trop technique ou lourd pour être manipulé à la main.
La séquence suivante a été construite pour cela :
tag XML → transfo VBA (icones,…) → XML intermédiaire → transfo XSLT → HTML final
A la question, est-ce que cela aurait pu être fait avec un seul outil, la réponse est non malheureusement. VBA ne permet pas de gérer simplement un grand volume de code HTML et d’autre part, le XSLT ne permet pas de réaliser des opérations complexes comme des calculs, la constitution d’une table des matières, des insertions de code à rechercher ailleurs, …
La liste des tags XML qui nécessitent d'être traités pour produire le HTML est la suivante :
Carte
L’exemple suivant est un extrait de la carte de la page Prosper 14-18.
Les cartes doivent être dans un fichier dédié.
<cartedesc MapTypeId="ROADMAP" ZoomLevel="8" Height="600">
<!-- attributs et valeurs destinés à Google map -->
<ligne lieu="Janvier 1915 à décembre 1917 dans la Vallée de l’Air" LatLng="49.2, 5.063152" profil="sLs" label="1915 et 1916
Argonne
2 citations"></ligne>
</cartedesc>
<!-- latitude/longitude fraction décimale (43.573354, 1.7848232) soit degré en minutes et secondes (43° 35.325’, 1° 46.087’) -->
<!-- font-size = en fonction du niveau de zoom toute valeur imagemagick : small medium large x-large xx-large, par défaut 20 -->
<!-- weight = toute valeur imagemagick : Thin ExtraLight Light Normal Medium DemiBold Bold ExtraBold=800 Heavy -->
<!-- color = toute valeur imagemagick, par défaut, la couleur de la famille -->
<!-- profil pour spécifier la taille des caractères de chacune des lignes de l’icone – peut être sL, Ls, sLs ou L par défaut -->
<!-- 
 ou line feed pour provoquer un changement de ligne dans le texte de l’icone -->
A la construction de la page, le programme VBA créé l'icône à l'aide d'ImageMagick puis transforme le XML dans la forme suivante :
<xdoc file="Sommaire\Prosper14-18\Z0t_201206-2222_009" img="null;" key="row-class:large;">
<fixed>
<cartedesc MapTypeId="ROADMAP" ZoomLevel="8" Height="600" latcenter=" 50.0182185" longcenter=" 3.904545">
<ligne lieu="Janvier 1915 à décembre 1917 dans la Vallée de l'Air" profil="sLs" label="1915 et 1916
Argonne
2 citations" var="Marker2"
icon="Prosper14-18_Map_2.png" lat="49.2" lng=" 5.06"></ligne>
</cartedesc>
<div class="clearfix"></div>
</fixed>
<float></float>
</xdoc>
La carte est enfin transformée en HTML à l'aide du code XSLT suivant qui principalement rajoute le code java nécessaire pour Google map :
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/xdoc/fixed">
<xsl:apply-templates select="cartedesc"/>
</xsl:template>
<xsl:template match="cartedesc">
<div id="map" class="mt-3 mb-5">
<xsl:attribute name="style">height:<xsl:value-of select="@Height"/>px;
</xsl:attribute>
<script>function initMap(){
var map = new google.maps.Map(document.getElementById(’map’), {zoom: <xsl:value-of select="@ZoomLevel"/>, center: {lat: <xsl:value-of select="@latcenter"/>, lng: <xsl:value-of select="@longcenter"/> }, mapTypeId: google.maps.MapTypeId.<xsl:value-of select="@MapTypeId"/> });
<xsl:for-each select="ligne">
var <xsl:value-of select="@var"/> = new google.maps.Marker({position: {lat: <xsl:value-of select="@lat"/>, lng: <xsl:value-of select="@lng"/>}, map: map, icon: "<xsl:value-of select="@icon"/>", title: "<xsl:value-of select="@lieu"/>" });
<xsl:value-of select="@var"/>.addListener(’click’, function() {infowindowA.open(map, <xsl:value-of select="@var"/>);});
</xsl:for-each>
}</script>
<script async="" defer="" src="https://maps.googleapis.com/maps/api/js?key=AIzaSyDMlGXBQfNm0J-WOOS_JQoC-uy5hF5mTms&signed_in=true&callback=initMap"></script>
</div>
</xsl:template>
</xsl:stylesheet>
Pour aboutir au code HTML suivant :
<div id="map" class="mt-3 mb-5" style=" height:600px;">
<script>function initMap(){
var map = new google.maps.Map(document.getElementById(’map’), {zoom: 8, center: {lat:50.0182185, lng:3.904545 }, mapTypeId: google.maps.MapTypeId.ROADMAP });
var Marker2 = new google.maps.Marker({position: {lat: 49.2, lng: 5.063152}, map: map, icon: "Prosper14-18_Map_2.png", title: "Janvier 1915 à décembre 1917 dans la Vallée de l’Air " });
Marker2.addListener(’click’, function() {infowindowA.open(map, Marker2);});
}
</script>
<script async="" defer="" src="https://maps.googleapis.com/maps/api/js?key=…;signed_in=true&callback=initMap"></script>
</div>
<div class="clearfix"></div>
Creation Fichier xdocs.XML
Au printemps 2024 il est apparu qu’il était possible de regrouper tous nos fichiers de données (plus de 20 000 à cette date) dans un seul fichier XML, ceci présente deux avantages :
Ce fichier (14 Mo) se charge instantanément dans Word et peut alors être utilisé pour y rechercher soit des tags soit du texte. C’est donc très pratique (merci la sélection XPATH) pour corriger / faire évoluer notre XML ou pour faire des recherches en mode texte.
C’est aussi l’occasion de faire un premier prétraitement dans nos xdocs en les regroupant en fonction de leur présentation : blog, galerie, large, ce qui ne sert à rien pour le moment mais pourrait permettre à terme de réécrire la construction des pages en partant de ce fichier plutôt que d’aller lire tous les fichiers xdocs.
<XMLpages>
<XMLpage famrep="Sommaire\Accueil" page_updated="24-05-20 10h26">
<xdocs row-class="blog">
<xdoc file="Sommaire\Accueil\-I0_180324-1056_1" img="null;" key="row-class:blog;">
<!-- contenu du fichier xdoc -->
</xdoc>
<xdoc file="Sommaire\Accueil\0000_231019-222419_11" img="null;" key="row-class:blog;">
<!-- contenu du fichier xdoc -->
</xdoc>
</xdocs>
<xdocs row-class="galerie">
<!-- tous les xdocs galerie consécutifs -->
</xdocs>
</XMLpage>
</XMLpages>
La variable torebuild est mise à jour avec le nom de la page à reconstruire à l’occasion de chaque écritrure d’un cDoc ou lors des créations de pages.
CustomXMLParts ?
Plutôt que dans un fichier externe il aurait été possible de le conserver dans un ActiveDocument.CustomXMLParts, toujours chargé en mémoire pour gagner en efficacité. Une fois compressée, l’impact pour le fichier Word n’aurait été que de 3 à 4 Mo.
Ce qui était moins clair, c’était l’impact sur la fiabilité de notre fichier Word avec par exemple des temps de sauvegardes plus longs et peut être quelques autres effets de bord dans la mesure ou de tels volumes ne sont pas la destination de Word.
D’un autre côté, les CustomXMLNode qui ont été utilisés savent indenter le XML ce qui est assez pratique pour l’afficher dans Notepad++. D’autre part, si un jour j’écris la création de page dans un langage compilé, les données d’entrées seront directement disponibles.